IC9600: A Benchmark Dataset for Automatic Image Complexity Assessment
Abstract
Image complexity (IC) is an essential visual perception for human beings to understand an image. However, explicitly evaluating the IC is challenging, and has long been overlooked since, on the one hand, the evaluation of IC is relatively subjective due to its dependence on human perception, and on the other hand, the IC is semantic-dependent while real-world images are diverse. To facilitate the research of IC assessment in this deep learning era, we built the first, to our best knowledge, large-scale IC dataset with 9,600 well-annotated images. The images are of diverse areas such as abstract, paintings and real-world scenes, each of which is elaborately annotated by 17 human contributors. Powered by this high-quality dataset, we further provide a base model to predict the IC scores and estimate the complexity density maps in a weakly supervised way. The model is verified to be effective, and correlates well with human perception (with the Pearson correlation coefficient being 0.949). Last but not the least, we have empirically validated that the exploration of IC can provide auxiliary information and boost the performance of a wide range of computer vision tasks.
Topics
Our dataset consists of eight semantic categories including abstract, advertisement, architecture, object, painting, person, scene, and transportation. To build such a diverse dataset, we initially collect images for each category from several popular datasets. Specifically, we select abstract and architecture images from AVA, advertisement images from Image and Video Advertisements, object images from MS-COCO, painting images from JenAesthetics, person images from WiderPerson, scene images from Places365, and transportation images from BDD100K. To further improve the diversity of each semantic category, we choose images from each dataset to contain sub-categories as many as possible. For example, the Places365 dataset contains 365 scenario categories. We randomly select 4 images from each scene category and get a total of 1,460 images for the scene category. The sampling strategies of other categories are similar to this. After the sampling process, we get around 1,500 images for each of the eight categories.


Advertisement

Architecture

Object
Paintings

Person

Scene
Transport
Annotations
We train annotators with a detailed tutorial including the purpose of the study and the basic concept of IC. To verify their abilities to distinguish different IC levels, we conduct a test consisting of a number of artificial image pairs that are simulated with simple geometries (e.g., triangle, square, and circle). We ask each participant to annotate each image by using 1-5 point scales. The final complexity score for each image is acquired by averaging the all collected labels and being normalized to [0,1].

Statistics
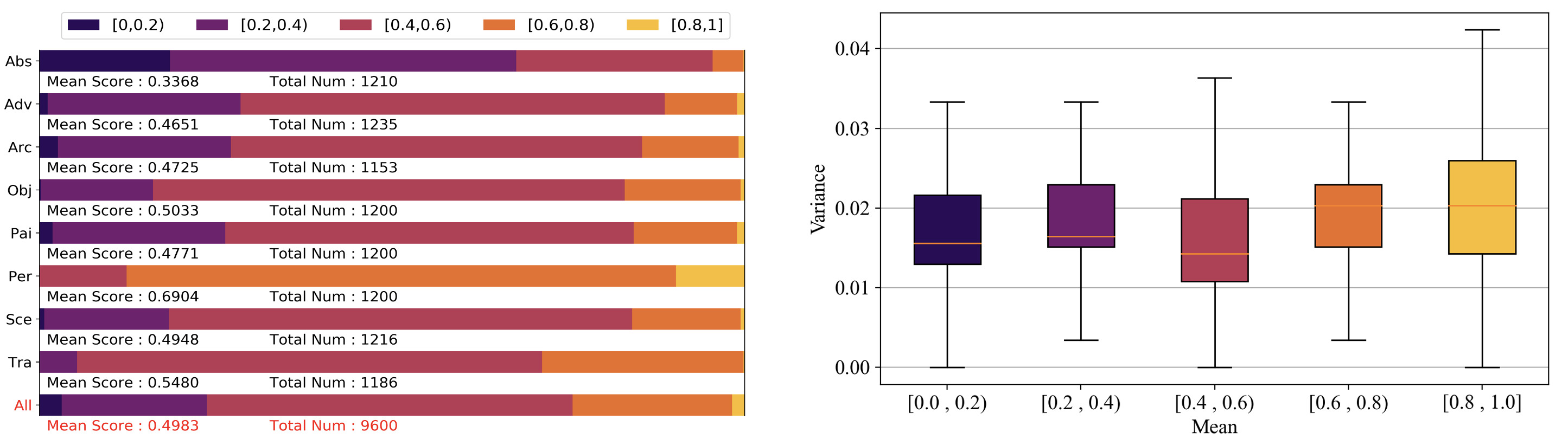
For each of the eight semantic categories, the score distribution is shown below (left). The category distribution of our dataset is relatively balanced since each category contains ~1,200 images. However, the distribution of complexity in different semantic categories varies from each other. As shown in the last row, we can see that nearly half of the images are assigned to medium scores (i.e., [0.4,0.6), and the whole dataset presents a symmetric Gaussian distribution centered at around 0.5, which reflects the IC distribution in the real world. The right figure presents the variance distributions of each split area. We can observe that most of the variances are lower than 0.04, which proves the high annotation consistency of our dataset.
Models
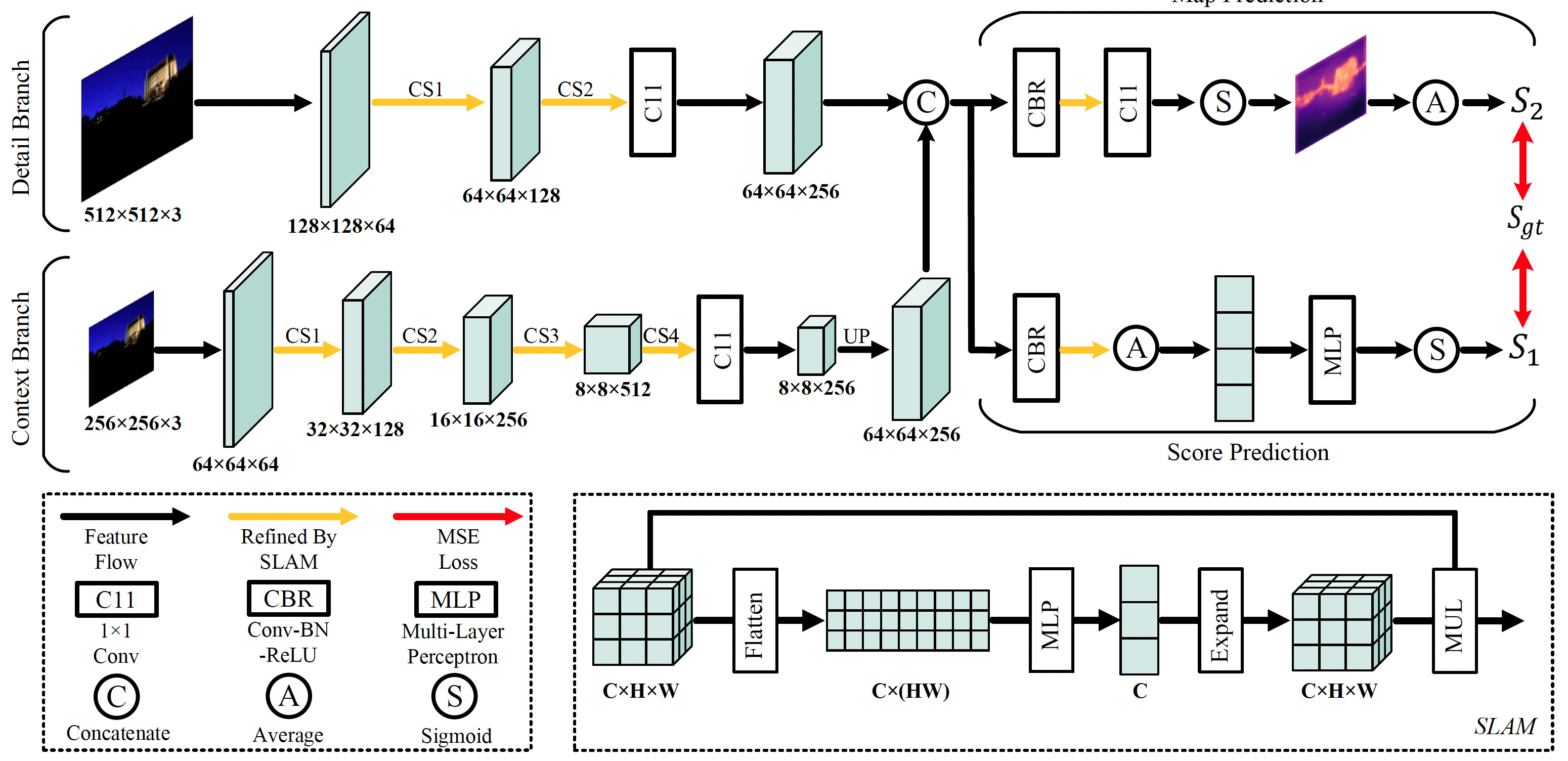
Based on the dataset, we propose a base model, namely ICNet, to extract powerful IC representations. ICNet is designed with two branches, i.e., detail branch and context branch. The detail branch utilizes a shallow convolutional network to capture local representations from high-resolution images, while the context branch aims to excavate contextual information from an image with a smaller size via a deeper network. Then the informative features from two branches are combined and sent to the following two heads, of which one predicts an IC score that represents the overall complexity of an image while another outputs an IC map that depicts the local complexity intensity of the image.
Visualizations
To make it easier to understand the IC, we show some visualization results predicted by our model in the figure below. We can find that the predicted scores are very close to the ground truth scores. The right image of each pair is the complexity map predicted from the detail branch. From these maps, we observe that our model can explicitly find the visually complex regions in an image. We can also find that the complex areas mostly focus on the positions that have a large amount of objects, textures, edges, variations, etc., and are hard for a person to explicitly describe.

Significance
To prove the significance of image complexity and explore its interactions with other image attributes, we have given quantitative analysis and justifications.
Image aesthetic presents a strong negative correlation with complexity.
Plenty of works indicate a purely inverse relationship between IC and the appraisal of aesthetics.
In favor of our high-performance IC evaluation model (e.g., ICNet), we have found new evidence to support the statement. Specifically, we conduct experiments on CUHKPQ and AADB datasets, which have long been widely used benchmark datasets in the area of image aesthetic
assessment (IAA).
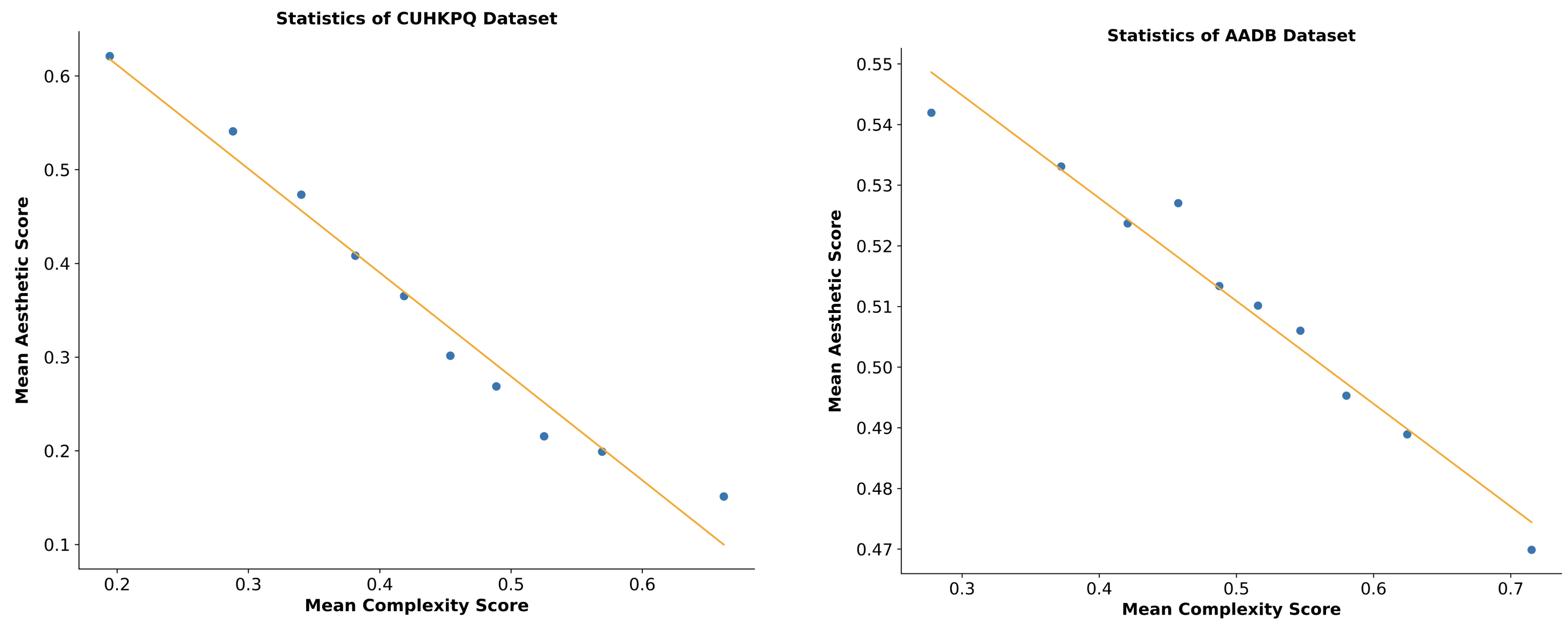 As shown in this figure, We uniformly
split all the images in each dataset into 10 intervals with complexity from lower to higher. We then calculate the
mean complexity and aesthetic score for each interval and scatter them on the plot. The orange straight line is a
linear fitting for these points.
We can observe a strong negative linear correlation
between image complexity and aesthetics in both two datasets, which implies that humans are
naturally rating simple images as more aesthetically attractive.
As shown in this figure, We uniformly
split all the images in each dataset into 10 intervals with complexity from lower to higher. We then calculate the
mean complexity and aesthetic score for each interval and scatter them on the plot. The orange straight line is a
linear fitting for these points.
We can observe a strong negative linear correlation
between image complexity and aesthetics in both two datasets, which implies that humans are
naturally rating simple images as more aesthetically attractive.
Distortions degenerate image quality and shake image complexity.
We conduct experiments on KADID which is a large-scale, well-annotated image quality
assessment (IQA) dataset built with diverse distortion varieties. Each image in this dataset is
manually generated by injecting various distortions into a reference image.
We calculate the complexity offset between each distorted image and its reference image in KADID dataset. The points formed by complexity offset and image quality of all images are plotted on the scatter, which
strongly suggests that the complexity fluctuation is synchronized with the distortions injected into an image.
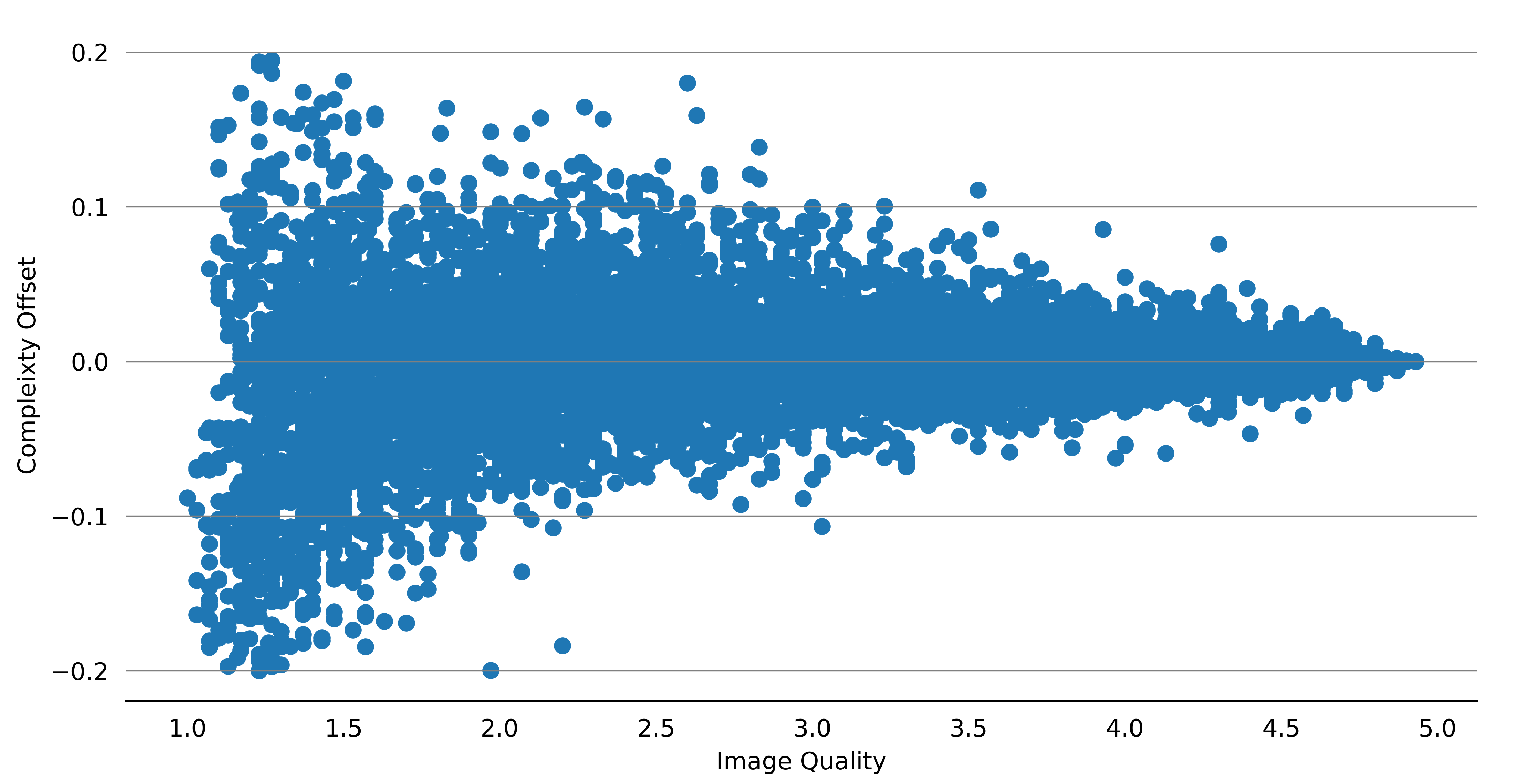 The distortions that degrade image quality are normally blurs, sharpening, spatial warp, etc., which
are also decisive factors of image complexity.
As shown below, the complexity of the image
degraded from blur largely drops along with the removal of spatial details. In contrast, images
with noise injected or sharpening inflicted show evident complexity rise due to the inflation
of texture and information.
The distortions that degrade image quality are normally blurs, sharpening, spatial warp, etc., which
are also decisive factors of image complexity.
As shown below, the complexity of the image
degraded from blur largely drops along with the removal of spatial details. In contrast, images
with noise injected or sharpening inflicted show evident complexity rise due to the inflation
of texture and information.
 In conclusion, image complexity is profoundly determined by the
factors that affect image quality, thus injecting distortions into images results in direct image
complexity shaking and quality dropping. The results also inspire us that IC can be potentially
incorporated into the image quality assessment as a strong indicator in the future. On the one
hand, the direction of IC moving (increase or decrease) can help us decide which distortion
type an image is being inflicted. On the other hand, the intensity of IC shaking can be applied
to assess the degree of distortion levels. By introducing auxiliary IC information, we can get a
more comprehensive understanding of how and how much an image is distorted, thus developing
adaptive strategies to tackle various image quality degeneration problems.
In conclusion, image complexity is profoundly determined by the
factors that affect image quality, thus injecting distortions into images results in direct image
complexity shaking and quality dropping. The results also inspire us that IC can be potentially
incorporated into the image quality assessment as a strong indicator in the future. On the one
hand, the direction of IC moving (increase or decrease) can help us decide which distortion
type an image is being inflicted. On the other hand, the intensity of IC shaking can be applied
to assess the degree of distortion levels. By introducing auxiliary IC information, we can get a
more comprehensive understanding of how and how much an image is distorted, thus developing
adaptive strategies to tackle various image quality degeneration problems.
Detectability of saliency decline with the increasement of complexity.
We explore how image complexity influences the detectability of salient objects on the widely used DUTS
dataset, which is a long-term recognized benchmark dataset in salient object detection. We
uniformly split images in DUTS into five subsets from lower complexity to higher. We
then evaluate the performance of the classical F3Net on each of the subsets, and the results
are shown below.
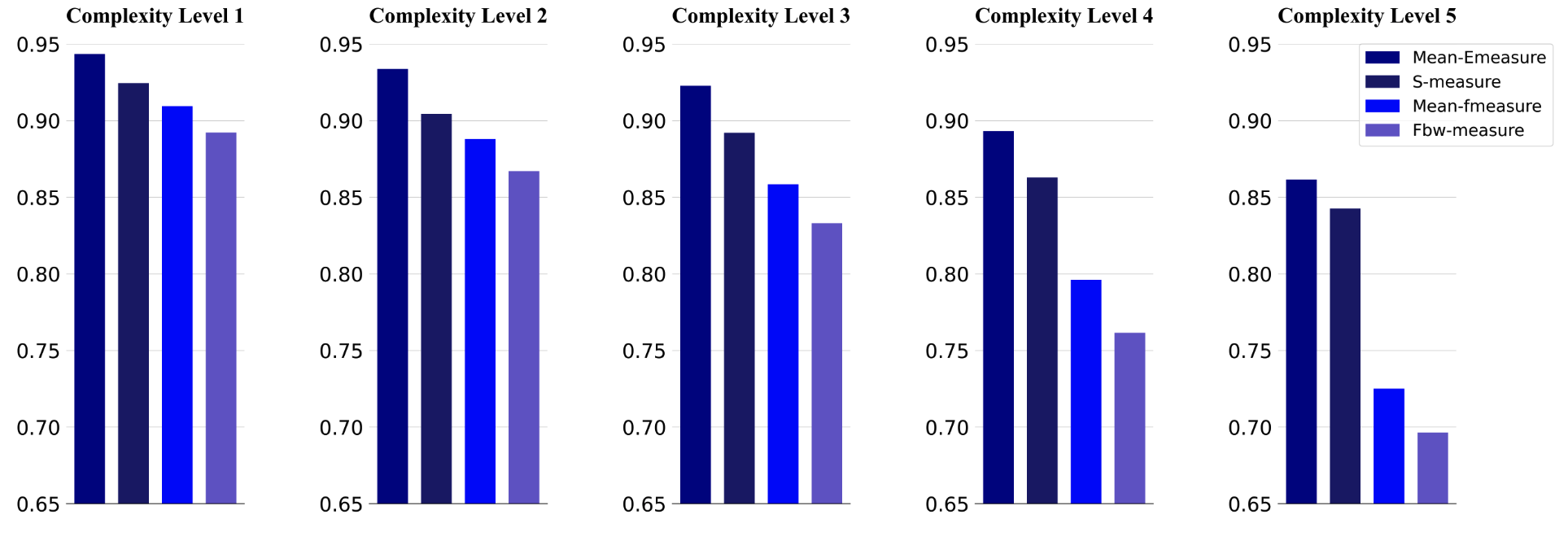 From the chart, we can conclude that with the increase of complexity
level, the performance on each metric drops consistently, which suggests that salient areas with
higher complexity are normally harder to be correctly detected.
We have also investigated the
underlying reasons and summarized them in the following two aspects:
From the chart, we can conclude that with the increase of complexity
level, the performance on each metric drops consistently, which suggests that salient areas with
higher complexity are normally harder to be correctly detected.
We have also investigated the
underlying reasons and summarized them in the following two aspects:
 First,
when images get more complex, more various and irregular elements slowly emerge and being
intertwined, thus the model starts to mismatch elements around the border between foreground
and background, which results in deteriorated detection performance. Second and more important,
the more complex images normally come with more elements and objects scattered around. Under
this scenario, it is relatively hard or improper to tell which objects are salient and which are
not due to the subjective nature of saliency. As a result, the
evaluation metrics may not be able to fairly reflect the performance of saliency detection when
it comes to images with high complexity. The above phenomenon and analysis inspire us that
complexity has a promising prospect adopting to the research of saliency.
First,
when images get more complex, more various and irregular elements slowly emerge and being
intertwined, thus the model starts to mismatch elements around the border between foreground
and background, which results in deteriorated detection performance. Second and more important,
the more complex images normally come with more elements and objects scattered around. Under
this scenario, it is relatively hard or improper to tell which objects are salient and which are
not due to the subjective nature of saliency. As a result, the
evaluation metrics may not be able to fairly reflect the performance of saliency detection when
it comes to images with high complexity. The above phenomenon and analysis inspire us that
complexity has a promising prospect adopting to the research of saliency.
Applications
We have explored several possible applications of IC in multiple computer vision tasks. In summary, introducing extra complexity information has been verified to be effective in a total of three application methodologies.
As an Auxiliary Task
Multi-task learning is a general and intuitive idea, and its reliable improvement for deep learning models has been proven in many influential works.
Its main idea is to add more supervision information related to the main task and optimize them simultaneously to help the model learn more robust features, thus improving the generalization ability.
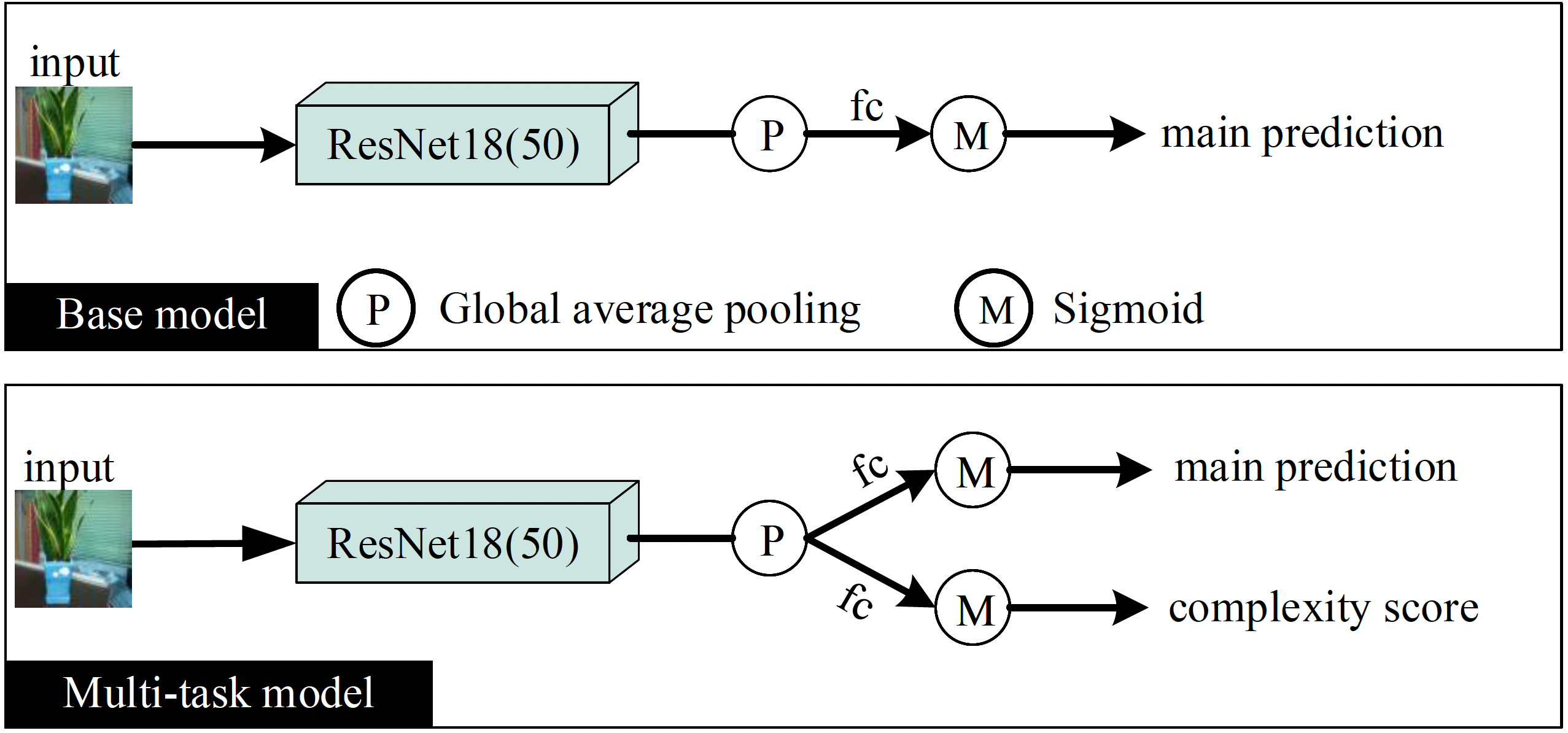 Here, we treat the complexity assessment as an auxiliary task, and generate the supervision signals
automatically using our trained ICNet.
Here, we treat the complexity assessment as an auxiliary task, and generate the supervision signals
automatically using our trained ICNet.
As a Complexity Modality
The proposed model ICNet can generate a pixel-level complexity map from the map prediction head. Such a fine complexity map can be considered as a kind of modality that provides guidance for models to understand the local
complexity degree of an images.
As we proved before, IC has a vital influence on the salient object detection. To verify whether the IC
information can help to find salient objects, we make two
experiments on the BBS-Net, which is designed
to find salient objects from the RGB modality and depth
modality by feeding them into two branches respectively.
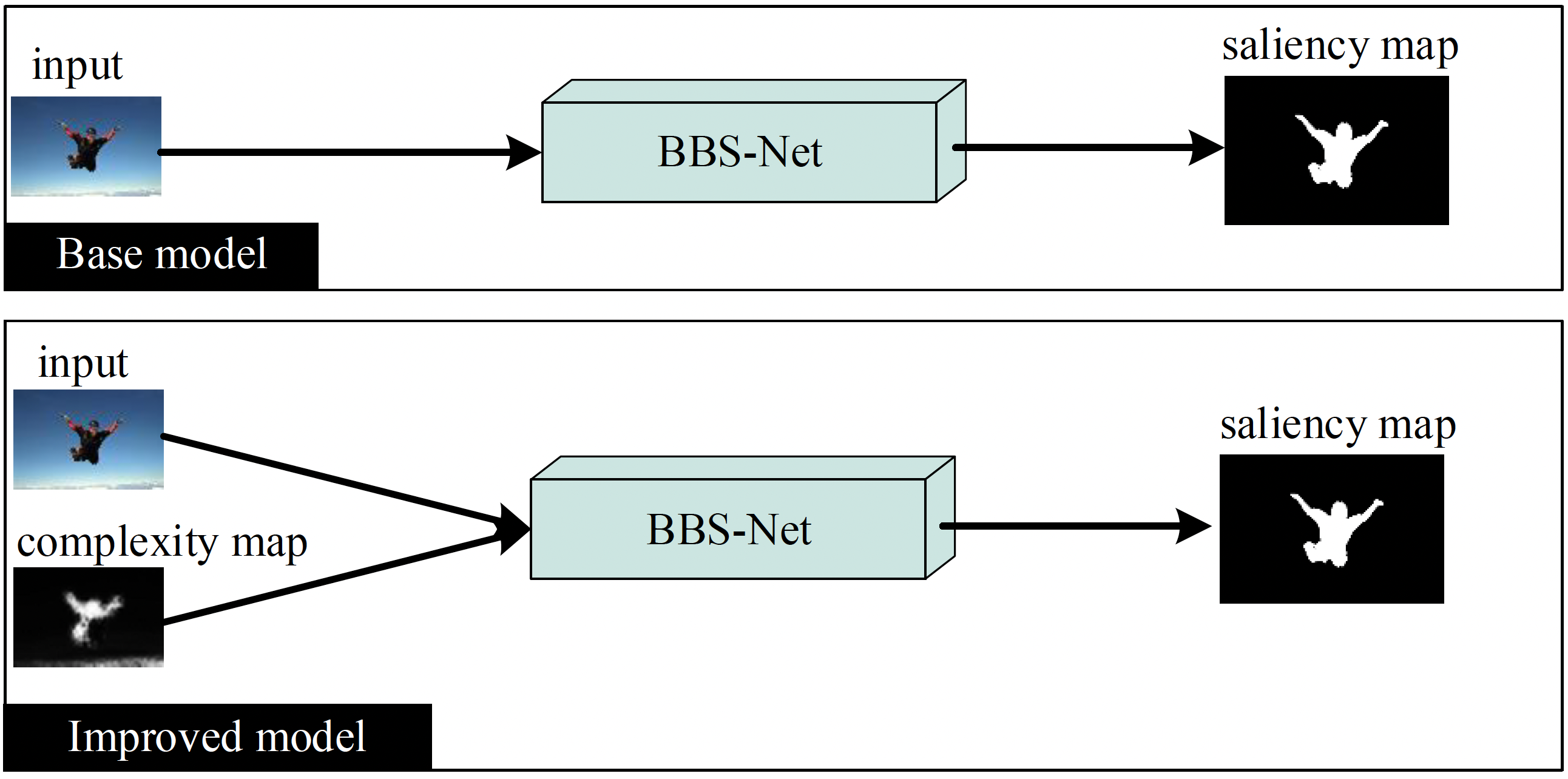 Since BBS-Net provides an efficient and general multimodality extracting and fusing strategy. The original depth channel can be simply replaced by complexity modalities, providing additional information that has strong correlation with saliency.
Since BBS-Net provides an efficient and general multimodality extracting and fusing strategy. The original depth channel can be simply replaced by complexity modalities, providing additional information that has strong correlation with saliency.
As a Prior Weight
It is intuitive that a visually complex image may be hard to segment. To address this, we can set high weights for the complex local areas to make the model focus more on them. For image segmentation, we give pixel-level weights for each image according to the IC map generated by our model (i.e., high complexity areas are given higher weights) when calculating the losses. For the base model, the pixel-wise cross entropy loss mask L for an image is defined as:
\(\bm{L}=-\sum_{j=1}^{C} \bm{G_j} \odot \ln \bm{Y_j}\)
,where C is the total classes, Gj and Yj are the ground truth map and predicted map for the class j, ⊙ means element-wise product.
For the improved model, the loss
mask L
\(\bm{L}^{\prime}=-\bm{W}\odot\sum_{j=1}^{C}\bm{G_j} \odot \ln \bm{Y_j}\)
,where W represents the complexity map produced by ICNet.
Quantitative Results
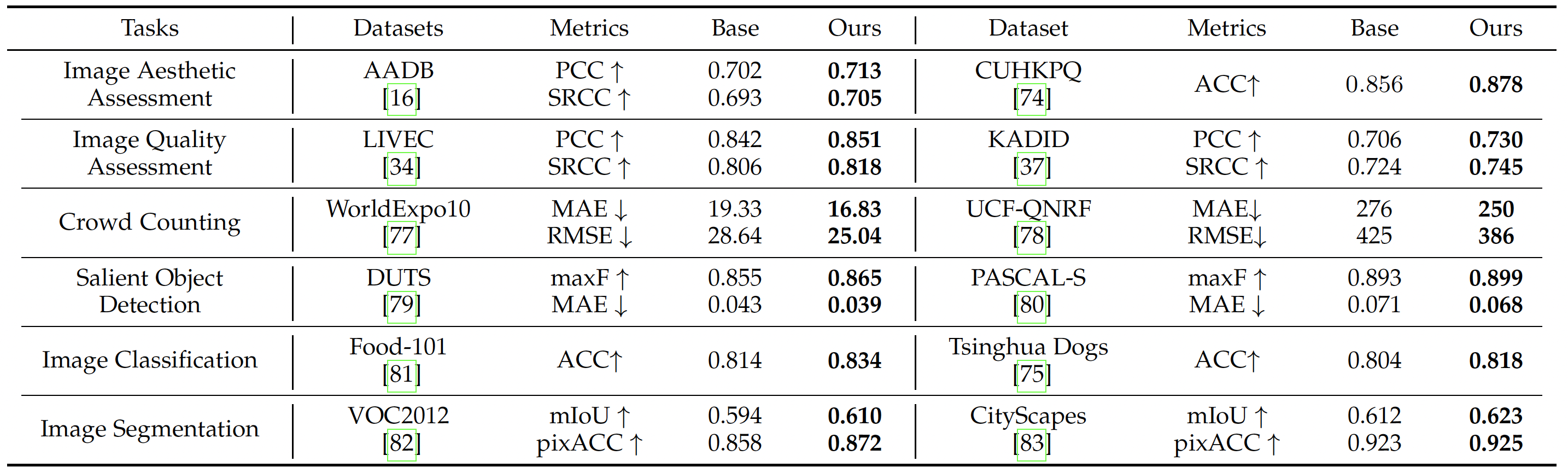
We have preliminary verified the significance of image complexity in benefiting six computer vision tasks, where the quantitative results can be found at this table.
Resource
-
If you need the IC9600 dataset for academic usage, please send an email explaining your use purpose to tinglyfeng@163.com. We will process your application as soon as possible. Please make sure that the email comes from your educational institution.
-
The source code of our model and pre-trained weights can be found here.
-
The chinese version of this paper can be downloaded from here.
-
The software we developed on the top of tkinter for the annotation of our dataset, you can download from here. Feel free to use or modify it if you find it helpful.
Citation
T. Feng, Y. Zhai, J. Yang, J. Liang, D. Fan, J. Zhang, L. Shao, and D. Tao, “IC9600: A benchmark dataset for automatic image complexity assessment” IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023.[PDF][中译版][Github]
Bibtex
@article{feng2023ic9600,
title={IC9600: A Benchmark Dataset for Automatic Image Complexity Assessment},
author={Feng, Tinglei and Zhai, Yingjie and Yang, Jufeng and Liang, Jie and Fan, Deng-Ping and Zhang, Jing and Shao, Ling and Tao, Dacheng},
journal={IEEE Transactions on Pattern Analysis and Machine Intelligence},
number={01},
pages={1--17},
year={2023},
publisher={IEEE Computer Society},
doi={10.1109/TPAMI.2022.3232328},
}
